Spark 2.4からサポートされた、Kubernetes上でのPySpark実行をやってみた。
環境
- MacOS 10.15.3
- Docker Desktop 2.2.0.0
※ Minikubeは未検証
動作イメージ
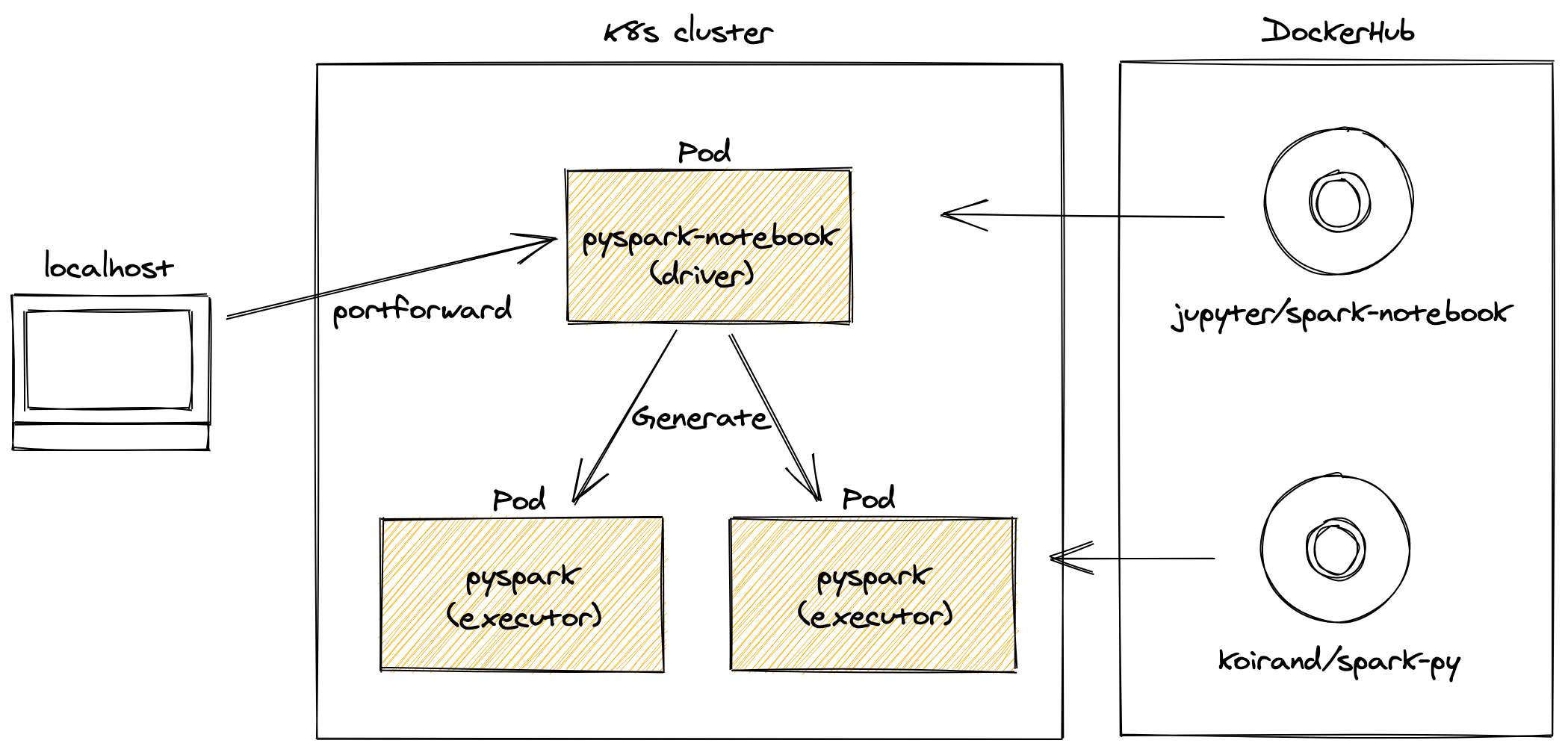
ソースコード
koirand/spark-notebook-on-k8s-example
k8sマニフェストとJupyter NotebookのExampleを格納してある。
k8sクラスタへのデプロイ
k8sマニフェストを作成してあるので、applyすれば動くはず。 メモリを結構食うので、事前にDocker Desktopの設定を変更してメモリのリソースを増やしておいたほうが無難。(4GBくらいあれば十分なはず)
$ kubectl apply -f manifest.yaml
spark-nsのネームスペースにもろもろリソースが作成される。
Jupyter Notebookから実行したかったので、Driver PodにはPySparkが同梱された jupyter/pyspark-notebook - Docker Hub を使用している。
また、Executor Podの自動生成に使用するサービスアカウントも作成している。
Jupyter Notebookのアクセストークンを確認
kubectl logs jupyter --namespace=spark-ns
Jupyter Notebookにポートフォワードで接続
kubectl port-forward jupyter --namespace=spark-ns 8888
http://localhost:8888 にブラウザでアクセスすればJupyter Notebookが使える。
PySparkの実行方法
example.ipynbをアップロードしてそのまま動かせば動くはず。
後片付け
kubectl delete -f manifest.yaml
ハマったところ
バージョンの不一致
Driver PodとExecutor PodでPythonとSparkのバージョンを完全に一致させないと動かない。Driver Podに使用した jupyter/pyspark-notebook - Docker Hub はPython3.7.4だが、SparkのソースコードからビルドしたExecutor用のDockerイメージはPython3.7.3になってしまいバージョンが一致しない。
結局、SparkのソースコードからビルドしたDockerイメージにPython3.7.4をインストールしたものを用意した。
koirand/spark-py: The patch for spark-py docker image.
これをExecutorに使うことでDriverとバージョンが一致する。
Driver podとExecutor pod間の通信
Executor podからDriver podへのアクセスにjupyter-svc.spark-ns.svc.cluster.localという名前を使用している。
conf.set("spark.driver.host", "jupyter-svc.spark-ns.svc.cluster.local")
DriverのサービスがHeadlessの場合はDriverとExecutor間でうまく通信ができたが、Headlessでない場合はなぜか通信ができなかった。ポートを開けてみたり色々試行錯誤してみたものの、うまくいかず原因不明。
ServiceAccount
k8sの環境によっては、defaultのServiceAccountではExecutorが起動できない。なのでExampleのマニフェストでは別途ServiceAccount(spark-sa)を作成して、adminロールをバインドし、そのサービスアカウントをDriver Podに付与している。